Java 7u6 last year brought with it a change to the implementation of String#substring. In previous versions of Java, Strings created by substring shared the same char array as the original String with an internal offset being used to make sure the correct characters were retrieved. This has the advantage of making substring a very cheap operation, O(1), but has the potential to create a significant memory leak. If a substring is taken of a long String, whilst the substring remains accessible the char array of the long String cannot be garbage collected. Java 7u6 (and later) change this and instead return truly independent Strings… but this requires copying part of the char array meaning substring is now an O(n) operation and hence repeatedly taking long substrings should be avoided.
A case where this behaviour can occur is in a tokenizer that after recognizing each token redefines the remaining String using substring. The longer the String in question the greater the effect on performance.
This behaviour is found in OPSIN’s parser hence accounting for a ~13% performance decrease in performance when moving from JDK6 to JDK7.
Resolving this performance regression can be tackled in at least two ways: Implementing a cheap substring operator using a decorating class (an example) or not using substring at all and instead keeping track of an index in the string from which to read. The first approach is hampered by String being final so a decorating class must instead implement CharSequence which is far less frequently used. Hence for OPSIN I choose the approach of keeping track of the index tokenization had reached:
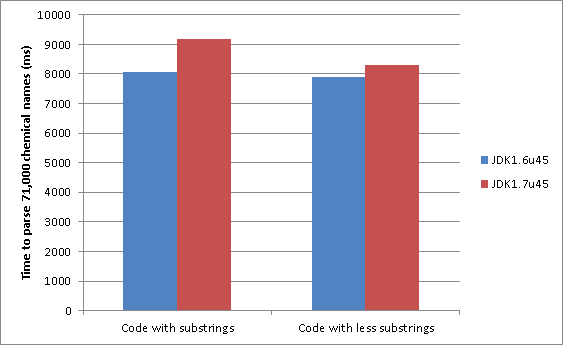
Substrings are still used to capture the tokens which may explain why the performance is still a bit slower.
More details on the substring implementation change:
http://www.javaadvent.com/2012/12/changes-to-stringsubstring-in-java-7.html
5 thoughts on “Java 6 vs Java 7: When implementation matters”
Comments are closed.