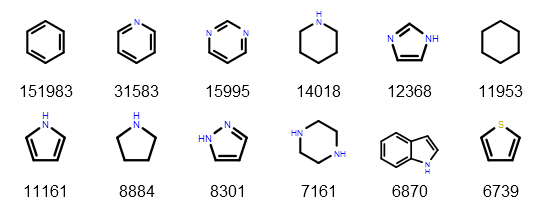
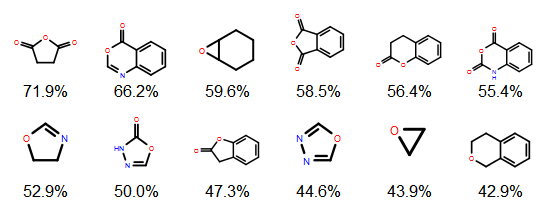
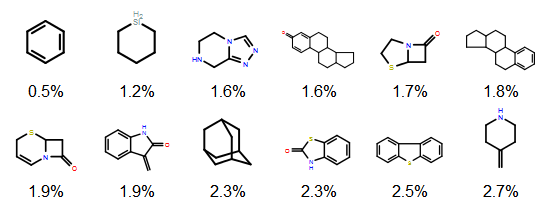
Earlier posts considered exact matches to sequence representations in PubChem. Now, let’s look at what should be considered similar matches. It is a failing of structural fingerprints that (to a first approximation) all oligopeptides are similar to all other oligopeptides because the paths (or atom environments) become saturated. A better way to measure similarity in this context would be to use edit distance. This can be done on the all-atom representation itself (e.g. using an MCS-based approach such as SmallWorld) or, more commonly for biopolymers, using a sequence representation.
Here we consider single mutations from a particular query. Some of the hits found will be due to an evolutionary process, and some due to humans exploring SAR. Naturally, there may also be some “mutations” due to errors by depositors – for the purposes of this blogpost we will minimise these by requiring strict matching on the conserved residues of the sequence (i.e. applying rules 1b, 2b, 3b from the previous blog post).
Sequence logos summarising the results are shown below for a set of queries against (a) the whole of PubChem, then (b) that subset derived from ChEMBL depositions.
| Peptide | PubChem | ChEMBL |
|---|---|---|
| casokefamide |  |
 |
| glumitocin |  |
 |
| neuromedin N |  |
 |
| setmelanotide |  |
 |
| spinorphin |  |
 |
| thymulin |  |
 |
Given that ChEMBL is a depositor into PubChem, it follows that the number of mutants found in ChEMBL must be a subset of those present in PubChem. It is still interesting to see that additional mutants are present, as it shows that PubChem has value above and beyond ChEMBL when it comes finding positions where SAR has been explored for a particular bioactive peptide.
Notes: Sequence logos were generated with WebLogo3. For more details see Noel O’Blog.